
距离我们上一次的年终回顾已经过去了六个月。随着年初 DeepSeek 引发的兴奋浪潮逐渐消退,人工智能似乎进入了一个停滞期。这种模式在检索增强生成(RAG)领域同样明显:尽管关于 RAG 的学术论文层出不穷,但近几个月来重大突破寥寥无几。同样,RAGFlow 近期的迭代也主要集中在增量改进上,而非发布重大新功能。这究竟是未来飞跃的序曲,还是稳步增长时期的开始?因此,进行一次年中评估是及时且必要的。
站在十字路口的 RAG——2025 年中对 AI 渐进式演进的反思
·13 分钟阅读
距离我们上一次的年终回顾已经过去了六个月。随着年初 DeepSeek 引发的兴奋浪潮逐渐消退,人工智能似乎进入了一个停滞期。这种模式在检索增强生成(RAG)领域同样明显:尽管关于 RAG 的学术论文层出不穷,但近几个月来重大突破寥寥无几。同样,RAGFlow 近期的迭代也主要集中在增量改进上,而非发布重大新功能。这究竟是未来飞跃的序曲,还是稳步增长时期的开始?因此,进行一次年中评估是及时且必要的。
2024 年即将结束,检索增强生成(RAG)的发展可谓波澜壮阔。让我们从多个角度全面回顾这一年的进展。
RAGFlow 2024 年的最终版本 v0.15.0 刚刚发布,带来了以下关键更新
此版本对 Agent 进行了多项增强,包括增加了 API、支持单步运行调试以及导入/导出功能。自 v0.13.0 版本以来,我们对 RAGFlow 的 Agent 进行了重构,以提高其易用性。此次新增的单步运行调试功能完善了这一过程,使得 Agent 工作流中的算子可以单独执行,从而帮助用户根据输出信息进行调试。
Infinity 是一款专为检索增强生成(RAG)设计的数据库,在功能和性能上都表现出色。它为密集和稀疏向量搜索以及全文检索提供高性能支持,并能对这些数据类型进行高效的范围过滤。此外,它还具备基于张量的重排能力,能够实现强大的多模态 RAG,并集成了与交叉编码器(Cross Encoders)相媲美的排序功能。
RAGFlow 响应社区需求,推出了 Text2SQL 功能。传统的 Text2SQL 需要对模型进行微调,这在企业环境中与 RAG 或 Agent 组件一同使用时,会显著增加部署和维护成本。RAGFlow 基于 RAG 的 Text2SQL 利用了现有的(已连接的)大语言模型(LLM),无需额外的微调模型,即可与其他 RAG/Agent 组件无缝集成。
RAGFlow v0.9 版本引入了对 GraphRAG 的支持。GraphRAG 最近由微软开源,据称是下一代检索增强生成(RAG)技术。在 RAGFlow 框架内,我们对 RAG 2.0 有一个更全面的定义。这个拟议的端到端系统以搜索为中心,由四个阶段组成。后两个阶段——索引和检索——主要需要一个专门的数据库,而前两个阶段定义如下:
搜索技术仍然是计算机科学领域的主要挑战之一,鲜有商业产品能够实现有效的搜索。在大语言模型(LLM)崛起之前,强大的搜索能力并未被视为必不可少,因为它并不能直接提升用户体验。然而,随着大语言模型日益普及,要将 LLM 应用于企业场景,就必须配备一个强大的内置检索系统。这也就是所谓的检索增强生成(RAG)——在将内容送入 LLM 生成最终答案之前,先在内部知识库中搜索与用户查询最相关的内容。
自 v0.8 版本起,RAGFlow 正式进入 Agentic 时代,后端提供了全面的基于图的任务编排框架,前端则提供了无代码的工作流编辑器。为什么要引入 Agentic?这个功能与现有的工作流编排系统有何不同?
一个朴素 RAG 系统的工作流程可以概括如下:RAG 系统使用用户查询从指定的数据源中进行检索,对检索结果进行重新排序,附加提示词,然后将它们发送给大语言模型(LLM)以生成最终答案。
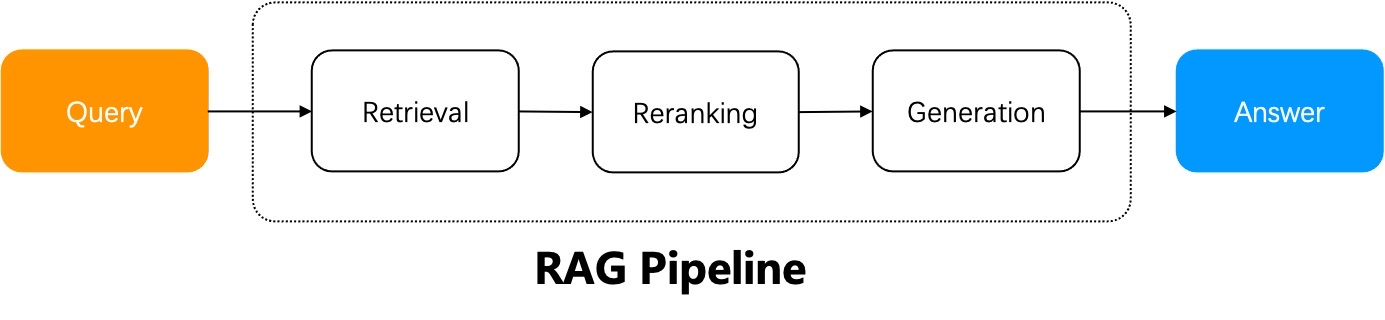
当用户意图明确时,一个简单的 RAG 就足够了,因为答案包含在检索到的结果中,可以直接发送给 LLM。然而,在大多数情况下,用户意图模糊是常态,需要通过迭代查询才能生成最终答案。例如,涉及总结多份文档的问题就需要多步推理。这些场景需要 Agentic RAG,它在问答过程中引入了任务编排机制。
Agent 和 RAG 相辅相成。Agentic RAG,顾名思义,是基于 Agent 的 RAG。Agentic RAG 与简单 RAG 的主要区别在于,Agentic RAG 引入了动态的 Agent 编排机制,该机制能够评判检索结果、根据用户每次查询的意图重写查询,并采用“多跳”推理来处理复杂的问答任务。
RAGFlow v0.6.0 已于本周发布,解决了自今年 4 月初开源以来出现的许多易用性和稳定性问题。RAGFlow 未来的版本将专注于解决 RAG 能力的深层次问题。我们不得不承认,市场上现有的 RAG 解决方案仍处于 POC(概念验证)阶段,无法直接应用于真实的生产场景。