
搜索技术仍然是计算机科学领域的主要挑战之一,鲜有商业产品能够实现高效搜索。在大型语言模型(LLM)兴起之前,强大的搜索能力并未被视为必不可少,因为它并不直接提升用户体验。然而,随着 LLM 的普及,将 LLM 应用于企业场景需要一个强大的内置检索系统。这也就是我们所说的检索增强生成(RAG)——在将内容提供给 LLM 生成最终答案之前,先在内部知识库中搜索与用户查询最相关的内容。
从 RAG 1.0 到 RAG 2.0,万变不离其宗
·8 分钟阅读
搜索技术仍然是计算机科学领域的主要挑战之一,鲜有商业产品能够实现高效搜索。在大型语言模型(LLM)兴起之前,强大的搜索能力并未被视为必不可少,因为它并不直接提升用户体验。然而,随着 LLM 的普及,将 LLM 应用于企业场景需要一个强大的内置检索系统。这也就是我们所说的检索增强生成(RAG)——在将内容提供给 LLM 生成最终答案之前,先在内部知识库中搜索与用户查询最相关的内容。
自 v0.8 版本起,RAGFlow 正式迈入 Agentic 时代,后端提供了全面的基于图的任务编排框架,前端则提供了无代码的工作流编辑器。为什么要 Agentic 化?这一特性与现有的工作流编排系统有何不同?
一个朴素 RAG 系统的工作流程可以概括如下:RAG 系统使用用户查询从指定的数据源中进行检索,对检索结果进行重新排序,附加提示词,然后将它们发送给大语言模型(LLM)以生成最终答案。
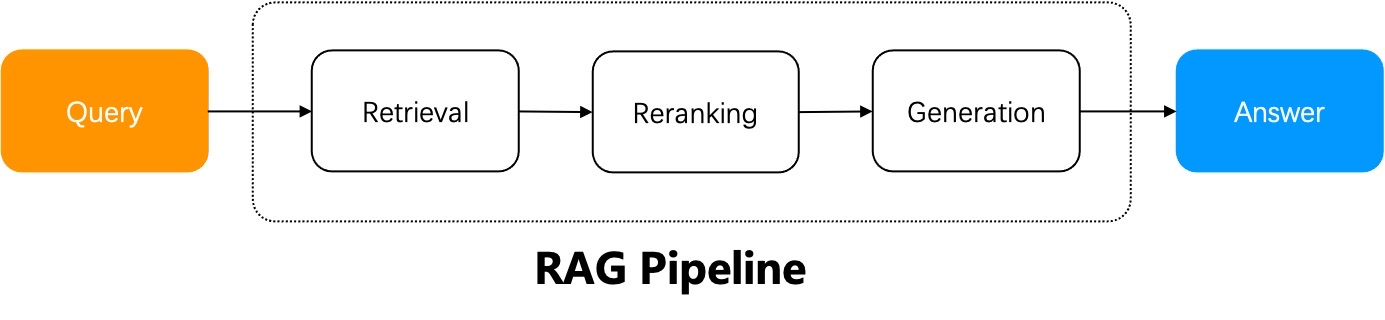
当用户意图明确时,一个简单的 RAG 就足够了,因为答案包含在检索到的结果中,可以直接发送给 LLM。然而,在大多数情况下,用户意图模糊是常态,需要通过迭代查询来生成最终答案。例如,涉及总结多份文档的问题就需要多步推理。这些场景需要 Agentic RAG,它在问答过程中引入了任务编排机制。
Agent 和 RAG 相辅相成。Agentic RAG,顾名思义,是基于 Agent 的 RAG。Agentic RAG 与简单 RAG 的主要区别在于,Agentic RAG 引入了动态的 Agent 编排机制,该机制可以评估检索结果,根据每个用户查询的意图重写查询,并采用“多跳”推理来处理复杂的问答任务。