
Infinity 是一款专为检索增强生成(RAG)设计的数据库,在功能和性能上都表现出色。它为稠密和稀疏向量搜索以及全文搜索提供了高性能能力,并支持对这些数据类型进行高效的范围过滤。此外,它还具备基于张量的重排功能,从而能够实现强大的多模态 RAG,并集成了与 Cross Encoder 相媲美的排序能力。

如下图所示,Infinity 本质上是一个面向多种数据类型的全索引数据库。
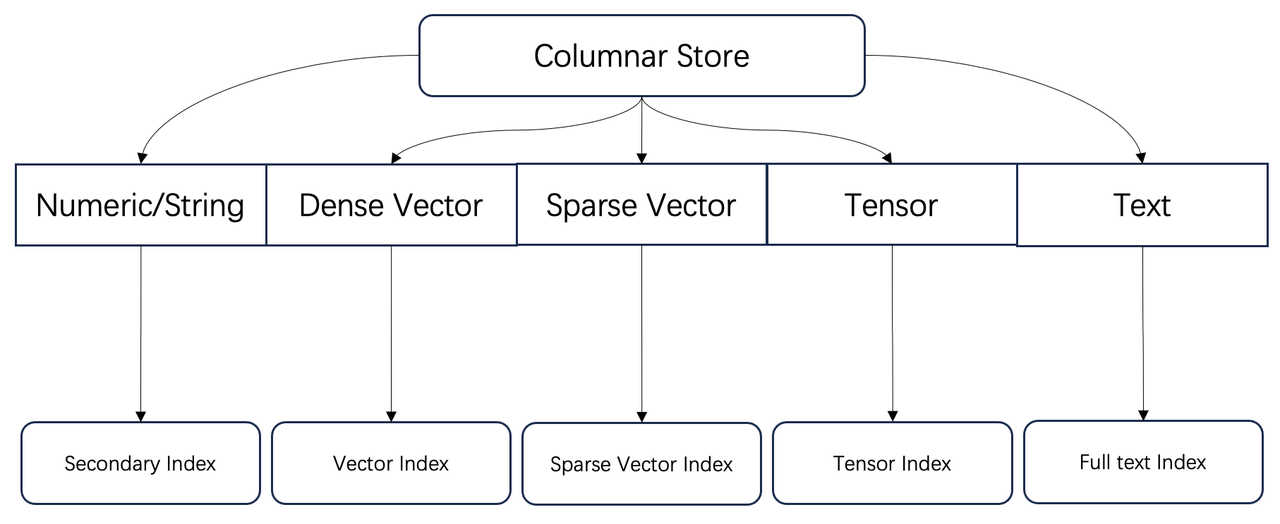
这些能力已被工程界和学术界公认为检索增强生成(RAG)的基础。那么,当前和未来的 RAG 系统还需要哪些额外的能力呢?
GraphRAG
首先,我们来看看 GraphRAG。这里的 GraphRAG 不仅指微软的开源项目,也指一种利用自动构建的知识图谱来辅助 RAG 检索的方法论。这种方法解决了问答中的“语义鸿沟”问题,即无法根据提出的问题找到答案。
既然涉及知识图谱,就不可避免地要谈到图数据库。图数据库旨在处理复杂的图结构查询。例如,考虑以下查询:返回用户 Alice 完成的所有两跳转账的所有源账户和目标账户。这可以用 SQL 表示如下
SELECT a.owner, c.owner
FROM Accounts a, b, c, Transactions t1, t2
WHERE b.owner = Alice AND a.owner=t1.From AND t1.To=b.owner AND t1.To=t2.From AND t2.to=c.owner
这需要两个表:一个账户表和一个交易表。操作如下:
- 在账户表中查找所有属于 Alice 的账户(b.owner = 'Alice')。
- 在交易表中找到所有向 Alice 发起交易的账户(a.owner = t1.From 且 t1.To = b.owner)。
- 识别 Alice 作为发起者的账户(t1.To = t2.From)。
- 最后,找到这些交易的最终目标账户(t2.To = c.owner)。
因此,我们可以观察到这类查询的三个特点:
- 虽然这个查询只涉及两个表,但它需要多次多表连接。
- 使用关系型数据库进行建模相当繁琐。
- 由于需要对多个表进行非顺序扫描,关系型数据库的查询效率非常低。每次操作通常只返回少量记录,这使得创建有效的查询计划变得困难。传统的关系型数据库很容易导致中间结果集过大,从而引发内存溢出(OOM)错误。
因此,图数据库的特点包括:
- 为了避免对表进行非顺序扫描,它们引入了索引,特别是倒排索引。倒排索引按列分别存储节点和边,并基于边构建索引,索引内容为节点 ID。
- 它们优化了多表连接;一些先进的系统实现了多路连接以实现最坏情况最优连接 [参考文献 1]。
回到知识图谱,我们是否需要如此复杂的图查询?撇开 GraphRAG 不谈,一个典型的知识图谱需要查询以根据给定实体检索相邻实体。更复杂的查询可能涉及子图遍历,以获取多个实体的邻居和多跳邻居。这些需求可以使用索引方便地实现。因此,对知识图谱的支持是图数据库一个相对简化的需求。
回到 GraphRAG,我们以 LightRAG [参考文献 2] 为例,来考察其中涉及的查询。选择 LightRAG 是因为它对 GraphRAG 查询提供了更全面和系统的总结,如下图所示。
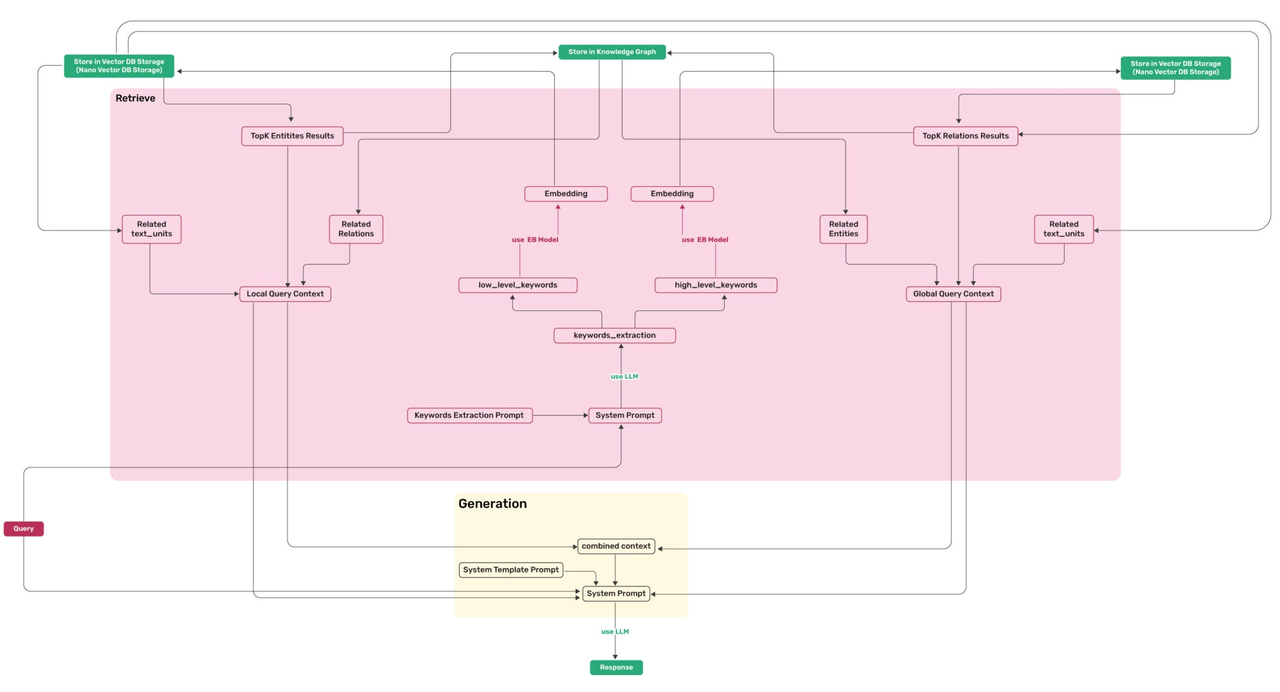
所需的查询如下:
- 查找与关键词向量最接近的 top 实体。
- 识别知识图谱中连接这些实体的关系。
- 查找与关键词向量最接近的 top 关系(边)。
- 识别知识图谱中由这些关系连接的实体。
很明显,GraphRAG 中对知识图谱查询的要求非常直接。在 GraphRAG 中,知识图谱的抽象和定义被简化了,实体之间的关系被简化为单一类型。这种简化是因为大语言模型(LLM)通常对实体和关系缺乏精确的定义,导致知识图谱通常作为检索增强生成(RAG)的辅助工具。最近,蚂蚁集团也公布了其 GraphRAG 方法 KAG [参考文献 3],它对知识图谱进行了更全面的定义,将实体间的关系扩展到六种类型,并引入了推理框架。然而,在数据检索本身并没有显著变化。因此,一个简单的想法产生了:移植一个精简版的图数据库能否满足当前和未来 GraphRAG 的需求?
最近,滑铁卢大学的资深搜索引擎研究员 Charles L. A. Clarke 提出了一种名为“标注索引”(Annotative Indexing)的新型索引方法 [参考文献 4]。其目的是统一列式存储、全文搜索和图数据库。“标注”一词指的是对倒排索引结构所做的调整;通过引入标注,倒排索引可以以更灵活的方式创建。基于这些观察,我们将探讨 Infinity 作为一个全索引数据库,能否满足 GraphRAG 当前和未来的需求。
如图所示,我们可以轻松地对知识图谱的实体和边进行建模。在 GraphRAG 中,知识图谱的实体和边被表示为文本描述,以及通过聚类这些实体及其摘要得出的社区。因此,所有这些文本都可以通过全文索引关联起来。Infinity 的全文索引提供了全面而强大的语法,不仅能进行相似度评分,还能**基于关键词进行过滤**。因此,在 <源实体名, 目标实体名> 字段上建立全文索引,可以方便地进行关键词过滤,从而实现基于边和实体的子图检索。此外,在 Infinity 内部,全文索引和向量索引无缝集成,可以针对 GraphRAG 实现高效的混合搜索。所有的边、实体,甚至社区都与向量一起被纳入全文搜索的范围,从而实现基于 GraphRAG 的双向混合召回。此外,如下面的 schema 所示,这些数据可以通过在原始文本块旁边简单地添加一个类型字段来存储在单个表中,从而有效地将 GraphRAG 和 RAG 合并为 HybridRAG。显然,采用一个具有丰富索引能力的数据库可以显著降低实现这些复杂逻辑的工程挑战。
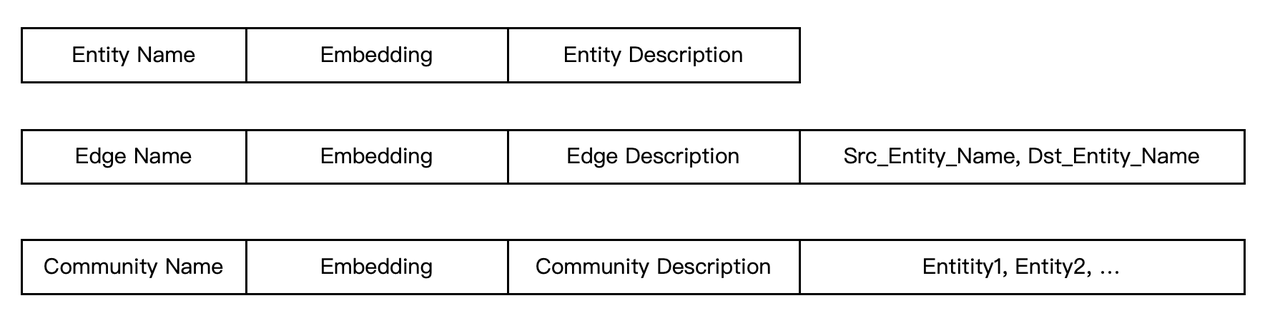
因此,可以得出结论,Infinity 目前无论现在还是将来都能满足 GraphRAG 的存储需求。展望未来,Infinity 将在计算层周围增加更多的执行逻辑,允许将一些应用层代码集成到数据库中,从而提升性能和可用性。例如:
- 一种 GraphRAG 直接将文本块视为图中的节点,块之间的相似度(基于多种选项)决定了边的存在。这也可以使用倒排索引进行建模。创建此类索引的任务可以在 Infinity 中作为后台作业实现。
- GraphRAG 需要与模型进行密切交互,未来不可避免地会引入一些图计算能力。例如,基于子图遍历结构生成图嵌入也可以作为 Infinity 中的后台任务执行。
此类任务可以通过后台作业或函数来完成,所有这些都可以在 Infinity 当前的引擎架构下执行,无需重大调整。这显然与 Infinity 伴随 RAG 发展的持续演进方向一致。
长期记忆
接下来,我们来考察与 Agent 密切相关的记忆管理,可以认为它是 Agent 的一个基本组件。在 RAGFlow 中,已经提供了一个 Agent 框架。目前,大多数 Agent 都与工作流紧密相连,以促进 RAG 与外部系统的交互,或通过工作流实现 Agentic RAG。然而,Agent 的未来在于以多 Agent 架构为代表的更智能的系统,这些系统将辅助大语言模型(LLM)提供推理能力。多 Agent 与 RAG 之间的交互将变得更加频繁,如下图所示。
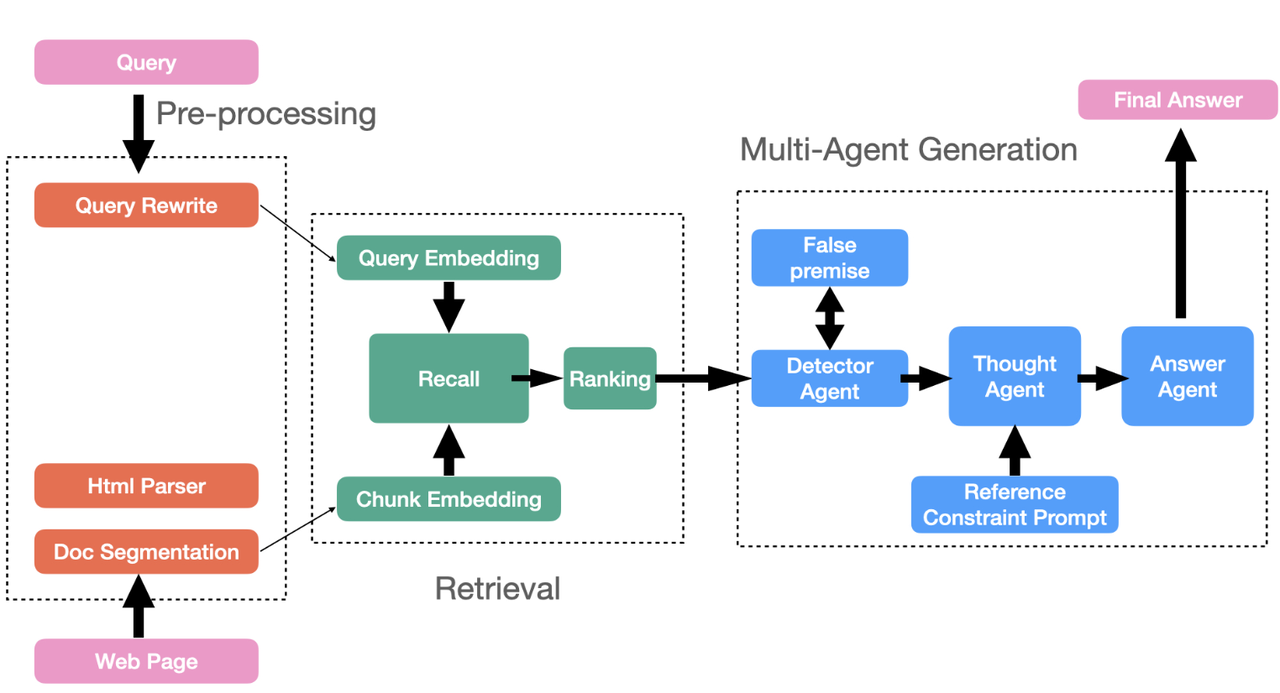
在这些架构中,Agent 需要管理自己的记忆,例如用户对话会话和个性化信息。许多 Agent 框架使用短期记忆模块来处理这些数据,并将其与长期记忆区分开来。前者依赖于临时内存数据;然而,随着 Agent 使用量的增加以及所有用户信息都需要被保留,一个更可靠的方法是使用长期记忆组件,具体来说就是数据库,以文本和向量格式存储所有上述用户信息。对于记忆管理,所需的接口基本上分为两类:
- 过滤:根据用户 ID、Agent ID 和时间范围,为特定的 Agent 和用户检索特定的记忆信息。
- 搜索:根据上下文信息(包括文本和向量)在用户记忆模块中查询相关信息。
由于 Agent 需要实时访问记忆,用于长期记忆管理的数据库不仅要支持上述两种需求,还必须保证实时性能:数据插入后必须立即可见。这实际上需要一种流式搜索能力——在 Infinity 中,所有索引都满足这一要求。
对于向量,索引构建是一个耗时的过程;因此,Infinity 对新插入的数据采用暴力扫描以实现实时查询。因此,Infinity 已经为支持即将到来的多 Agent 系统做好了充分准备。
Infinity,作为一款专为检索增强生成(RAG)设计的数据库,已经发展到具备全面的服务能力。在 RAGFlow v0.14 的最新版本中,Infinity 已被集成为 Elasticsearch 的替代方案。经过充分的测试和验证,Infinity 将成为 RAGFlow 的首选方案,并随着时间的推移解锁许多高级功能。敬请关注 Infinity 和 RAGFlow 的更新!
https://github.com/infiniflow/infinity
https://github.com/infiniflow/ragflow
参考文献
- https://github.com/kuzudb/kuzu
- https://github.com/HKUDS/LightRAG
- https://github.com/OpenSPG/KAG
- Annotative Indexing, arXiv preprint arXiv:2411.06256
- HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction, Proceedings of the 5th ACM International Conference on AI in Finance, 2024
- TCAF: a Multi-Agent Approach of Thought Chain for Retrieval Augmented Generation, 2024 KDD Cup Workshop for Retrieval Augmented Generation