
RAGFlow v0.9 版本引入了对 GraphRAG 的支持,这是微软最近开源的一项技术,据称是下一代检索增强生成(RAG)。在 RAGFlow 框架内,我们对 RAG 2.0 有一个更全面的定义。这个提出的端到端系统以搜索为中心,由四个阶段组成。后两个阶段——索引和检索——主要需要一个专用的数据库,而前两个阶段定义如下:
- 数据提取:利用各种文档模型来确保为索引提供高质量的数据,从而避免“垃圾进,垃圾出”的问题。
- 文档预处理:在提取的数据发送到数据库之前,可以实施可选的预处理步骤,例如文档聚类和知识图谱构建。这些步骤主要增强多跳问答和跨文档查询。虽然 GraphRAG 确实很先进,但它只是 RAG 2.0 流程的一部分。
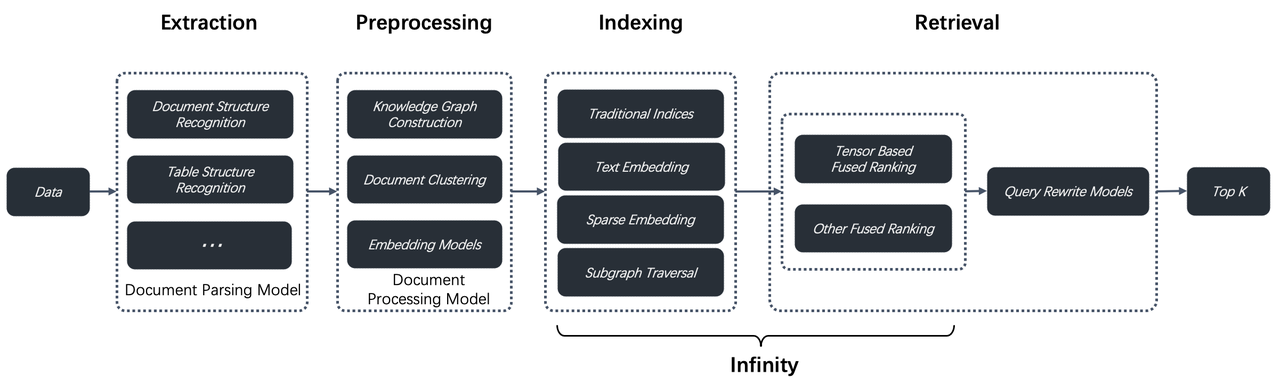
从 v0.9 版本开始,这部分功能已集成到 RAGFlow 中。下面,我们将探讨增加这一功能的原因以及它与微软的 GraphRAG 有何不同。
知识图谱对于提升 RAG 的效果至关重要。朴素的 RAG 系统通常检索与用户查询内容相似的内容,因此可能无法总是提供正确的答案。像摘要类问题本质上是面向查询的摘要(QFS),可以通过使用知识图谱来处理。知识图谱可以有效地根据文本相关性聚合内容,并在对话过程中基于这些聚合内容生成摘要,从而提高最终回答的准确性。许多现代 AI 搜索解决方案都采用了这种方法。顺便提一下,RAGFlow 早期版本中引入的 RAPTOR 也采用了文本聚类来提高检索效果;而专门针对知识图谱的方法可以根据命名实体生成更具“层次性”的结果,为 QFS 查询提供更高的准确性和更全面的回答。如今,多项研究已经证明,知识图谱可以通过提供额外的上下文信息来提升 RAG 输出的效果,并使大语言模型(LLM)在许多情况下生成更具可解释性的答案。这就是为什么 GraphRAG 的推出迅速在社区引起了巨大关注。在 RAG 兴起之前,已经有很多尝试利用知识图谱进行问答(KGQA)。然而,其在企业中广泛应用的一个主要障碍一直是知识图谱构建的自动化和标准化。随着 LLM 和 RAG 的出现,自动化这一过程变得更加可行,而 GraphRAG 是其中最引人注目的例子之一。
GraphRAG 极大地简化了知识图谱的抽象和构建过程,并极大地方便了标准产品的推出。因此,我们在 RAGFlow 中实现 GraphRAG 时参考了这种方法。RAGFlow 在文档预处理阶段引入了知识图谱构建作为一项可选功能,以支持更复杂的问答场景。它还对原始的 GraphRAG 进行了以下改进:
- 引入了去重步骤。在原始的 GraphRAG 中,提取的命名实体未经去重直接使用,这可能导致将同义词如“2024”和“2024年”或“IT”和“信息技术”视为不同实体的问题。这个问题在学术上称为实体解析,通常涉及复杂的算法。然而,RAGFlow 利用 LLM 进行去重,因为 LLM 可以被广义地看作是隐式的知识图谱。
- 减少 Token 消耗:GraphRAG 天生会消耗大量 Token,因为它在其原始实现中需要将所有用户上传的文档多次发送给 LLM。这导致了巨大的 Token 使用量,特别是对于使用 SaaS 服务的 RAG 系统。RAGFlow 通过确保所有文档只向 LLM 提交一次来优化此过程,从而最大限度地减少不必要的 Token 消耗。为了从根本上解决这个问题,可以使用更小的独立模型来构建知识图谱。一个成功的例子是 Triplex,它是基于 30 亿参数的 Phi-3 进行微调的,与使用 LLM 相比,可以节省数倍的成本。未来,RAGFlow 也将提供类似的解决方案,以进一步降低与 GraphRAG 相关的构建成本。
以下是 RAGFlow 版本的 GraphRAG 的演示:
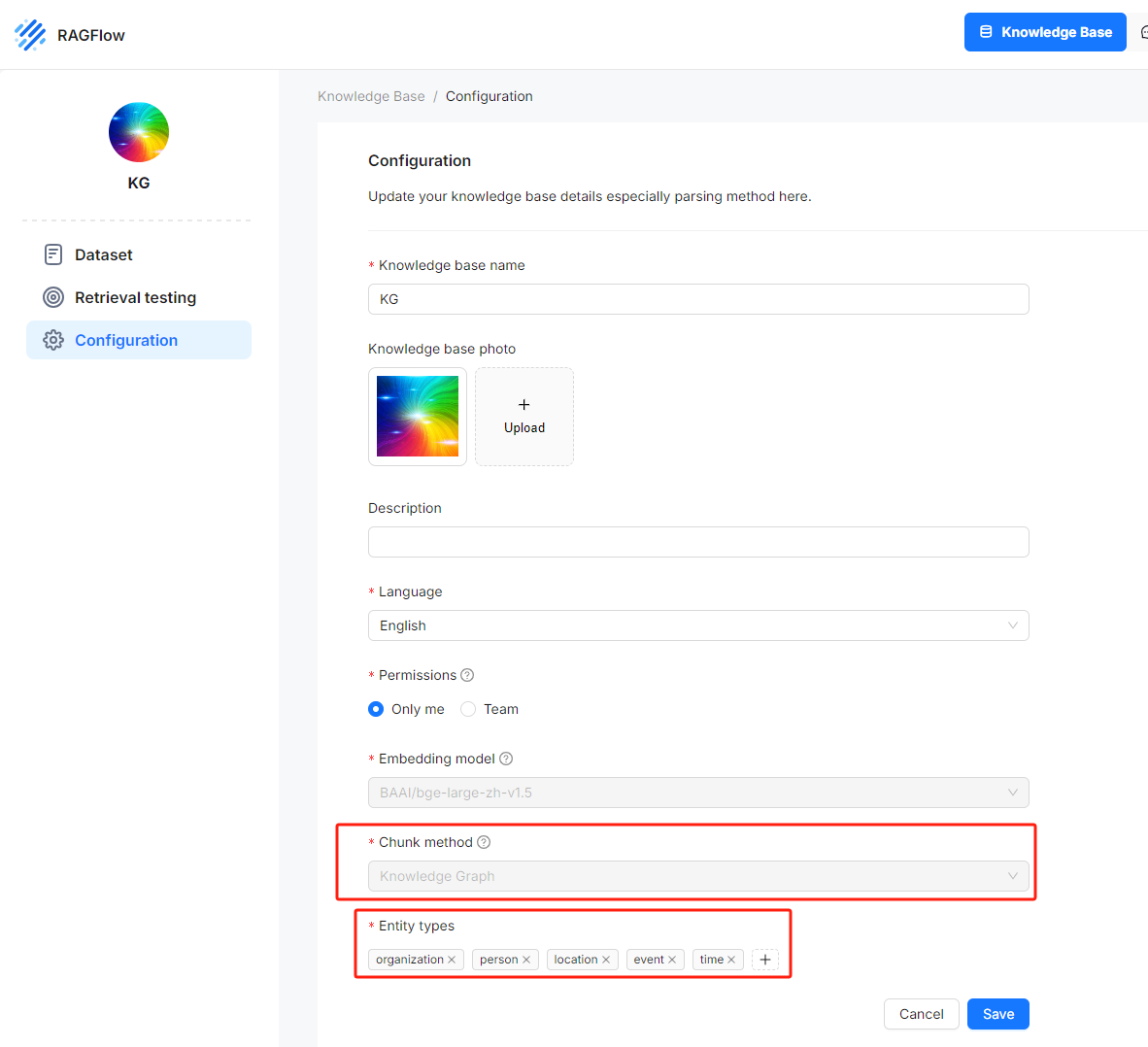
在文档解析阶段,用户可以为特定的知识库选择“知识图谱”作为分块方法。他们还必须定义希望 LLM 提取的命名实体类型,例如“组织”、“人物”和“地点”,如下图所示:
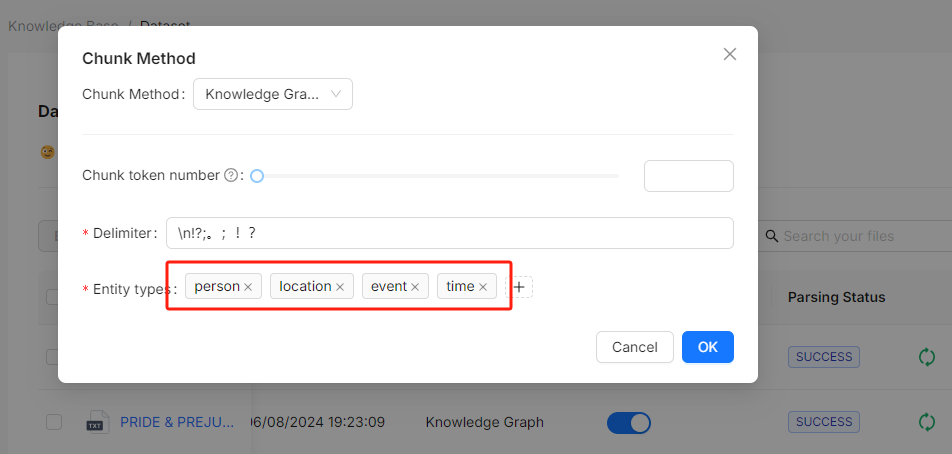
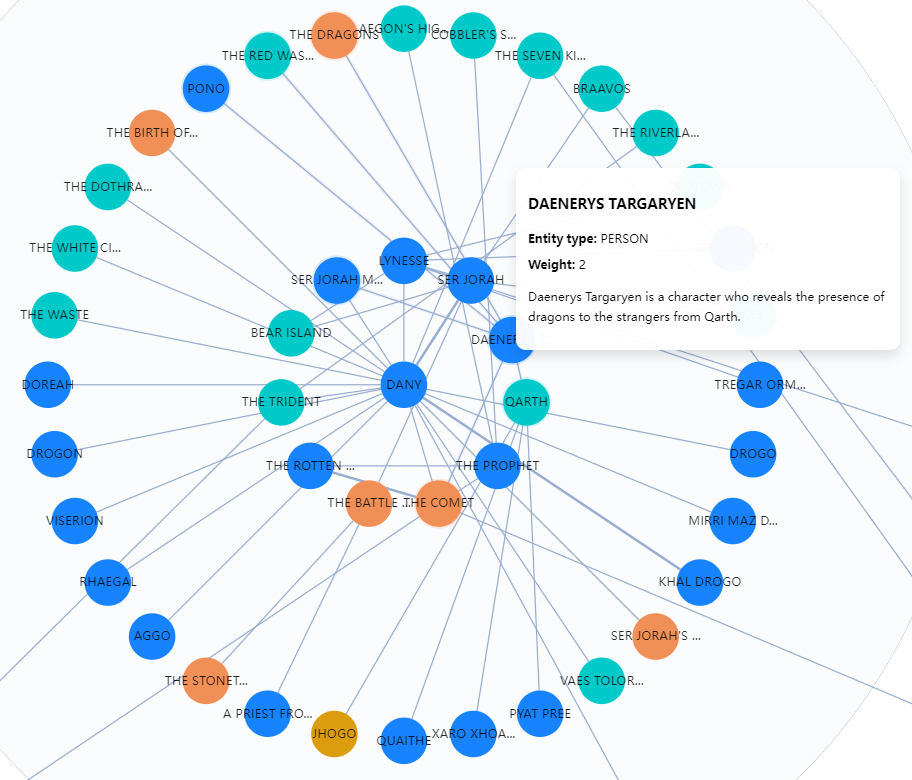
选择分块方法后,您可以触发 LLM 提取实体并构建知识图谱。RAGFlow 会可视化地展示这些知识图谱,包括节点名称、节点描述和“社区”。
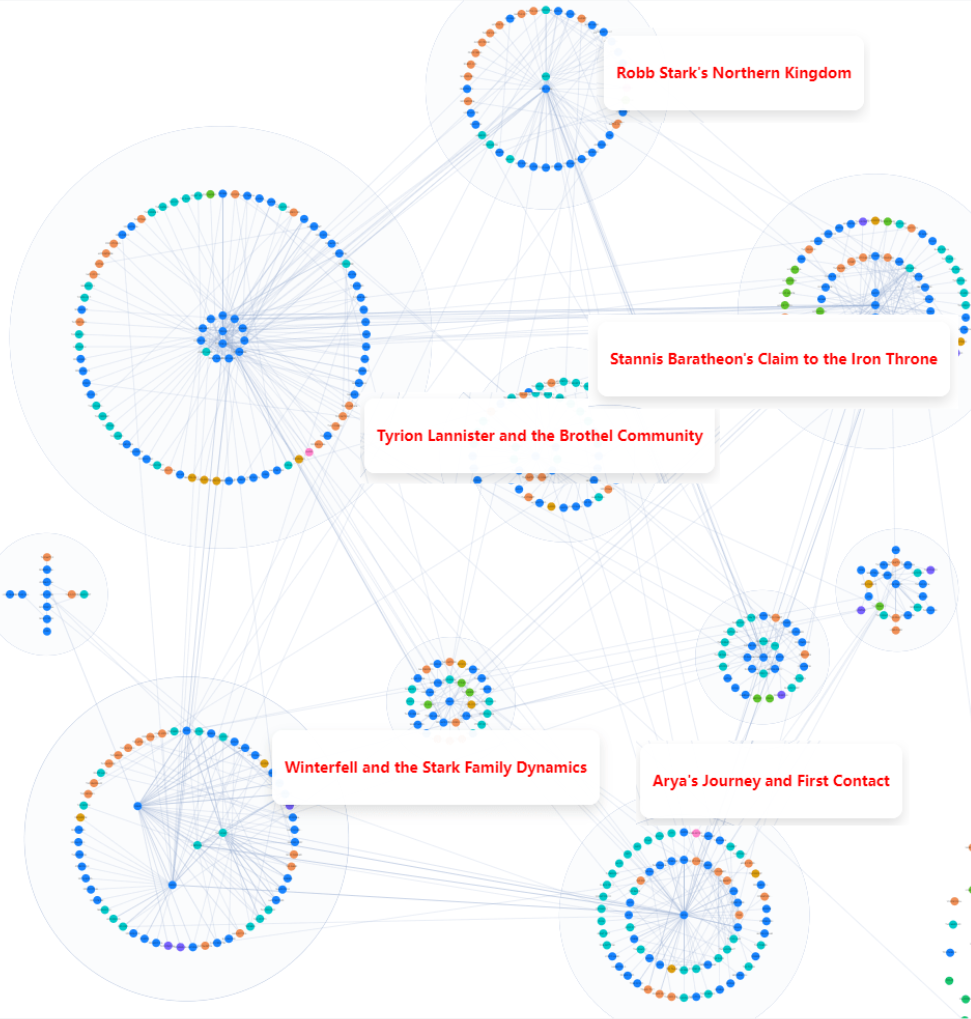
知识图谱也可以显示为思维导图:
知识图谱的可视化对于用户调试对话至关重要。目前,RAGFlow 支持使用任何已连接的 LLM 来生成知识图谱。然而,不同的 LLM 在数据提取方面的能力各不相同,提取知识图谱失败可能导致对话错误。在这种情况下,可以使用可视化工具来查看生成的知识图谱并分析对话。
目前,RAGFlow 的知识图谱生成是文档级别的,这意味着它不支持为知识库中的所有文档构建一个统一的知识图谱。换句话说,RAGFlow 中当前版本的 GraphRAG 无法关联从多个文档生成的知识图谱。此功能需要显著更多的内存和计算资源。RAGFlow 将在后期根据用户反馈重新考虑此功能。
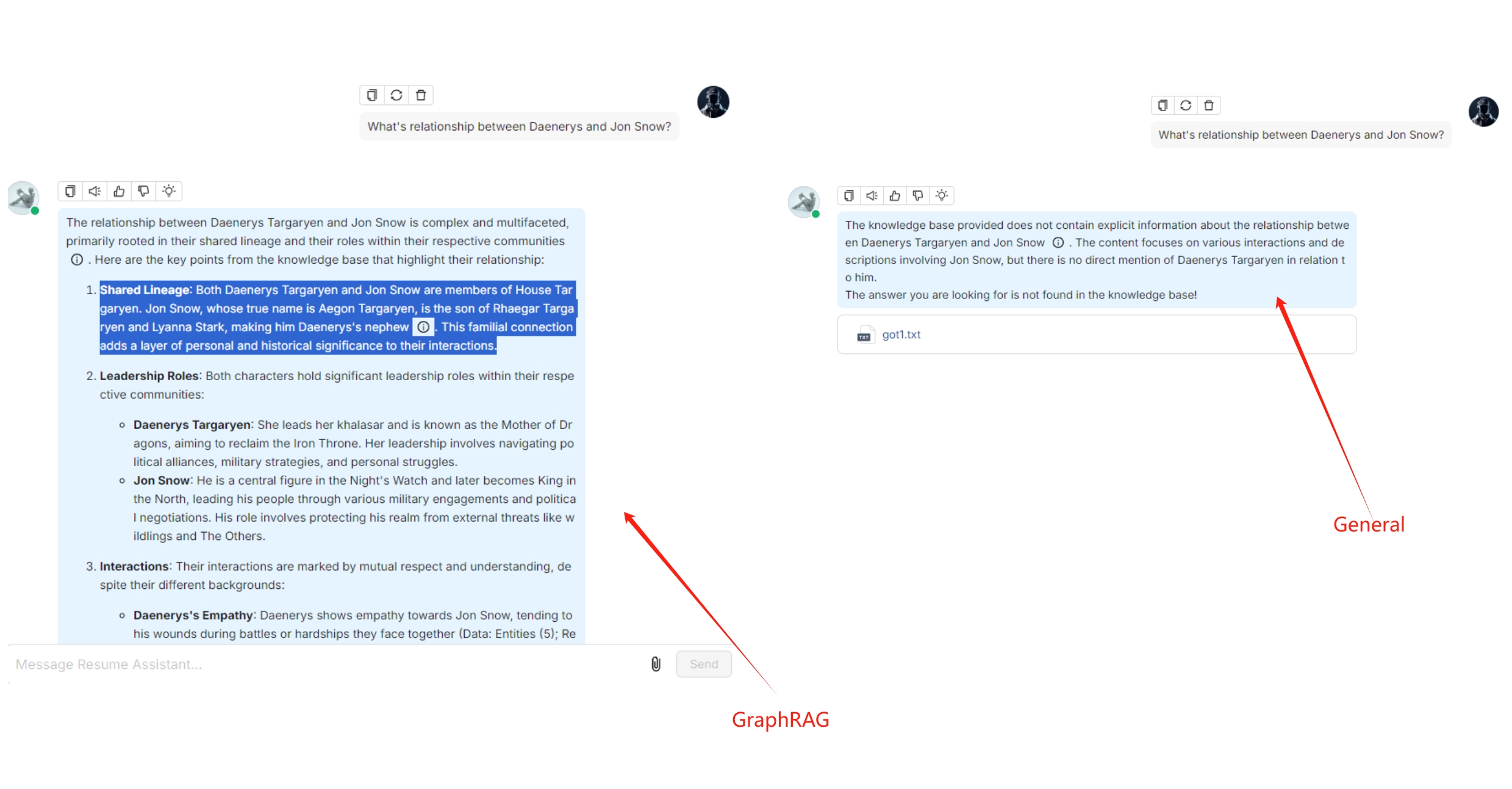
下图并列展示了从《权力的游戏》生成的对话。左边的对话是使用 GraphRAG 生成的,它表明对于涉及嵌套逻辑的多跳查询,GraphRAG 提供了更深入、更全面的答案。右边的对话是基于使用 GENERAL 解析方法解析的文档,结果显示无答案。
总而言之,RAGFlow 对 GraphRAG 的实现旨在为 RAG 自动化构建知识图谱。虽然 GraphRAG 消除了与传统知识图谱算法相关的许多复杂性,但它并非在 RAG 应用中使用知识图谱的最终解决方案。在真实的企业场景中,有相当一部分数据不适合构建知识图谱,或者为所有数据构建知识图谱可能不具成本效益。实际上,知识图谱还有许多其他应用,例如使用知识图谱重写查询。RAGFlow 计划在不久的将来支持这些功能。
参考文献
- GraphRAG, https://github.com/microsoft/graphrag
- From Local to Global: A Graph RAG Approach to Query-Focused Summarization, https://arxiv.org/abs/2404.16130
- HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models , https://arxiv.org/abs/2405.14831