
本周,我们发布了 RAGFlow v0.6.0,解决了自今年四月初开源以来出现的许多易用性和稳定性问题。未来,RAGFlow 将专注于解决 RAG 能力的深层次问题。坦率地说,市面上现有的 RAG 解决方案仍处于 POC(概念验证)阶段,无法直接应用于真实的生产场景。这主要是因为 RAG 本身存在许多尚未解决的问题。
数据质量:RAGFlow 提供开源的数据清洗模型和分块模板,以提高数据质量,并将持续迭代和优化这些内置模型和工具。数据检索:在问题意图明确的场景下,需要多路召回(multiple recall)来检索相关上下文,而当前的 RAGFlow 集成了具备多路召回能力的数据库。答案检索挑战:在许多情况下,仅用问题内容进行搜索不一定能捕捉到答案的上下文。问题和答案的语义之间显然存在差距需要弥合。
我们可以从多个方面来解决上述最后一点,包括:利用外部知识图谱进行查询重写和用户意图理解;通过引入 Agent 提高答案质量,使大语言模型(LLM)能通过增加对话交互来优化答案;为 LLM 检索更长的上下文以寻找答案。
RAGFlow 的路线图包含了针对这三个方面的功能。今天,我们将讨论 RAGFlow 最近在主分支(或 Docker 的 dev 标签)中增加的一项实验性功能,以解决上述最后一点——基于 RAPTOR 实现长文本 RAG。
RAPTOR 的思想源于今年早些时候发表的一篇题为“Recursive Abstractive Processing for Tree Organized Retrieval”的论文。如下图所示,该论文提出了一种增强的文档处理方法:对文档内容进行分层聚类。
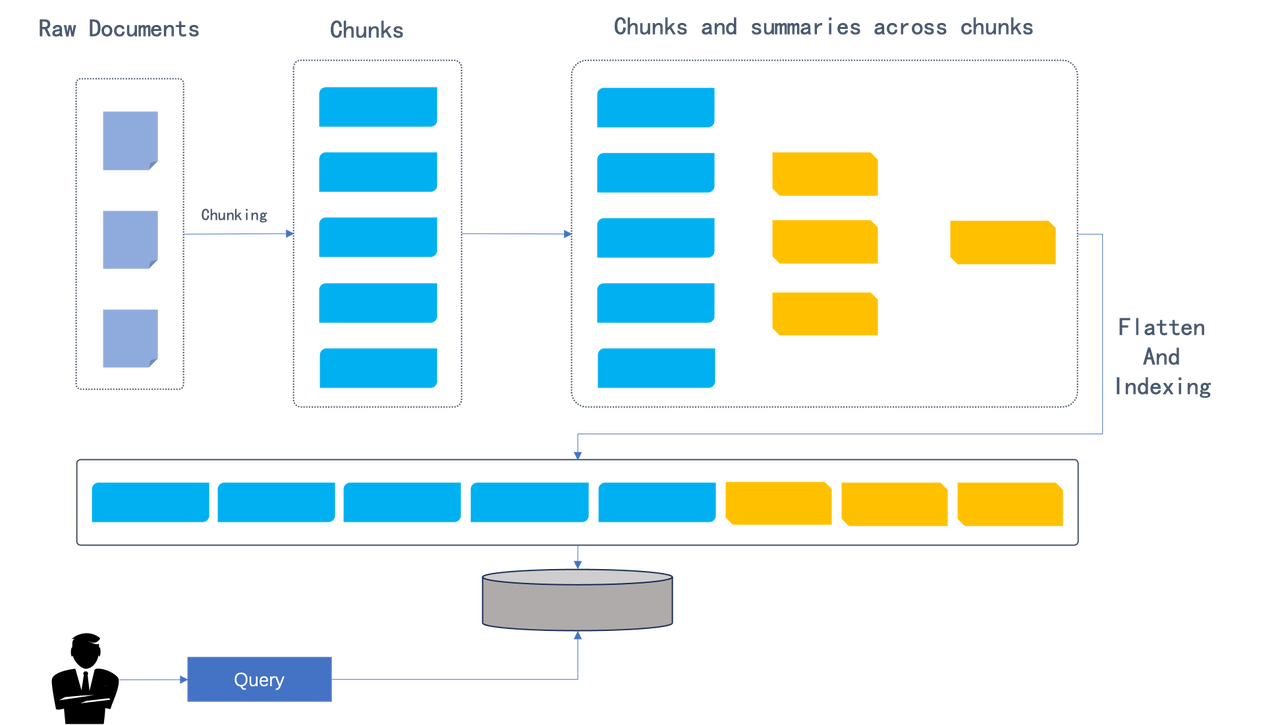
在将原始文档分割成块(chunks)后,RAPTOR 以递归和分层的方式对这些块进行聚类:聚类过程从叶节点(图中的蓝色块)开始,并通过嵌入(embedding)将叶节点的信息总结成更高级别的信息。该过程递归执行,形成一个从叶节点开始的“树”状结构。聚类过程的产物是摘要(summaries),可以由 LLM 生成。聚类和摘要生成的使用至关重要,因为它能捕捉到处理复杂主题查询和问答任务中多步推理所需的更精细的细节。RAPTOR 论文讨论了两种检索聚类内容的流程,如下图所示。
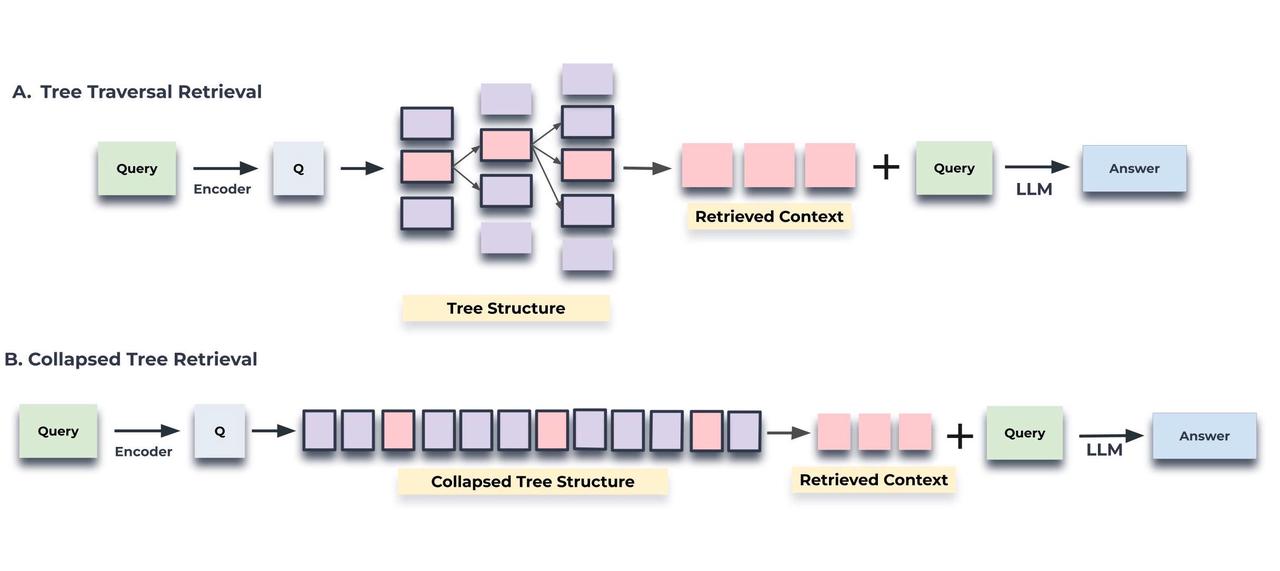
第一种流程保留了树形结构:检索从根节点开始,并在整个树形结构中分层进行。这种检索方式实现起来稍显复杂,并且对多路召回“不友好”。
第二种流程为了检索而将树形结构扁平化。这种方式易于实现,并且能与多路召回自然地结合。
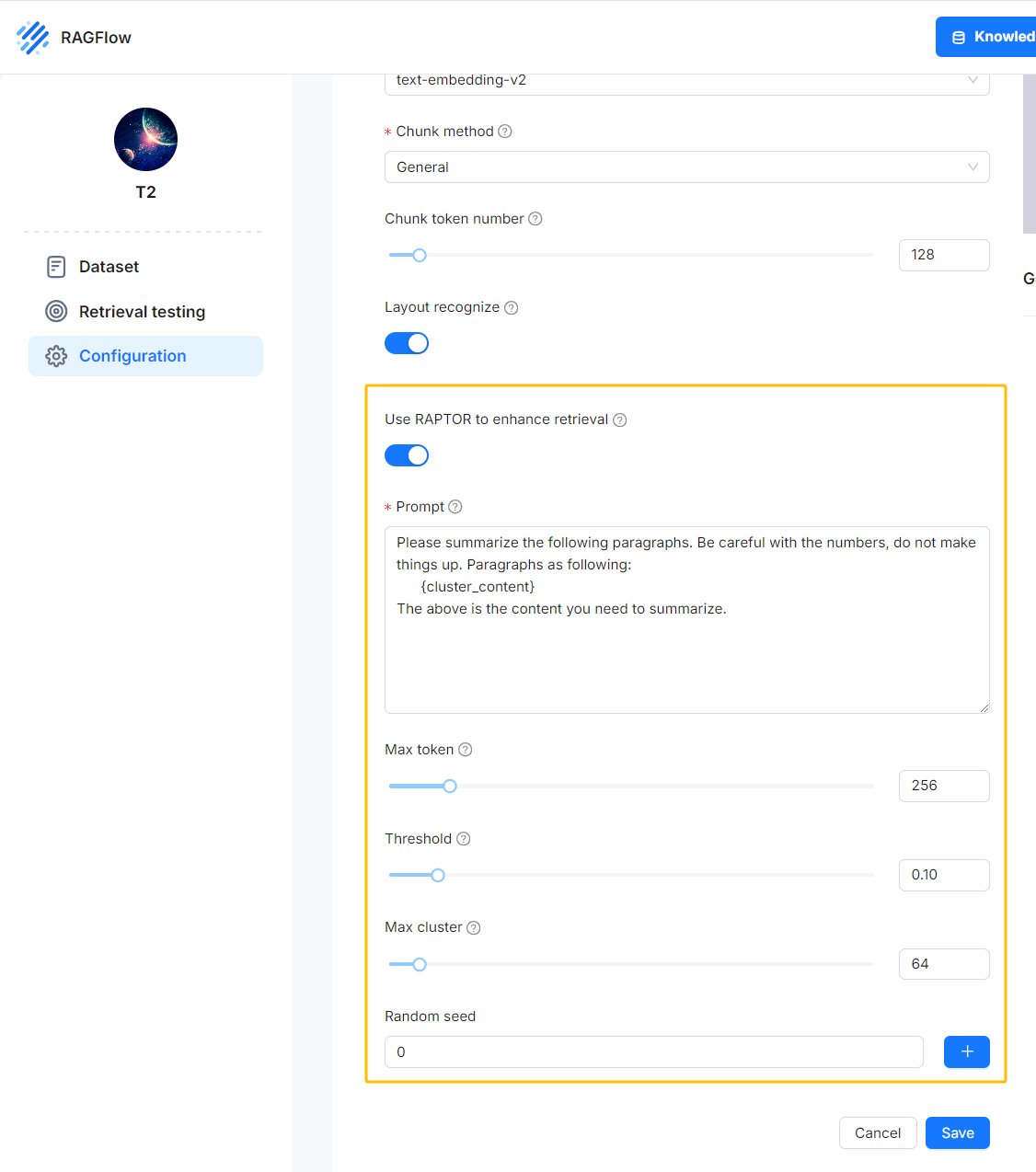
RAGFlow 实现了论文中提出的扁平化树形结构检索方案:在使用 Deepdoc 解析文件后,您可以选择开启 RAPTOR 开关,以进行聚类和摘要生成。原始的块和生成的摘要随后被发送到数据库,以建立全文索引和向量索引。后续操作与传统的 RAG 解决方案类似。
请注意,RAPTOR 开关默认是关闭的,因为启用此功能会消耗更多的 token 配额。
当您需要更好地理解长上下文窗口时,可以激活这个 RAPTOR 开关,从聚类结果中生成摘要。
如下图所示:左半部分是 LLM 根据聚类结果生成的摘要。RAGFlow 将这些摘要可视化,它们将与原始数据一起用于 RAG 的检索过程。
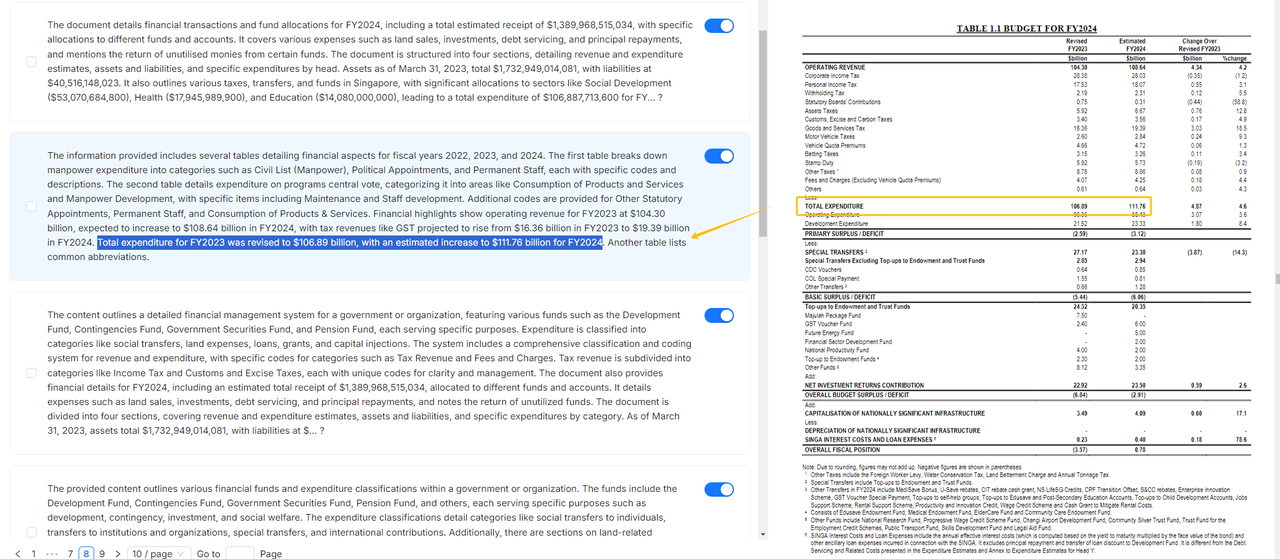
RAPTOR 帮助 LLM 更好地理解上下文。这是因为聚类树结构中的上层节点对文本有更“宏观”的理解,这对于需要跨块总结或答案无法从相应上下文中直接检索的多跳问答(multi-hop Q&A)场景非常有利。
RAGFlow 采用 RAPTOR 方法,是其为解决 RAG 检索痛点所做的尝试之一。在未来的版本中,我们将带来更多改进。敬请期待!