启用 RAPTOR
一种用于长上下文知识检索和摘要的递归摘要方法,平衡了广泛的语义理解和精细的细节。
RAPTOR(Recursive Abstractive Processing for Tree Organized Retrieval,树状组织检索的递归摘要处理)是一种在2024年一篇论文中引入的增强型文档预处理技术。RAPTOR 旨在解决多跳问答问题,它对文档块进行递归聚类和摘要,以构建一个分层树结构。这使得在长文档中可以进行更具上下文感知能力的检索。RAGFlow v0.6.0 将 RAPTOR 集成到其数据预处理流水线中,用于文档聚类,该过程位于数据提取和索引之间,如下图所示。
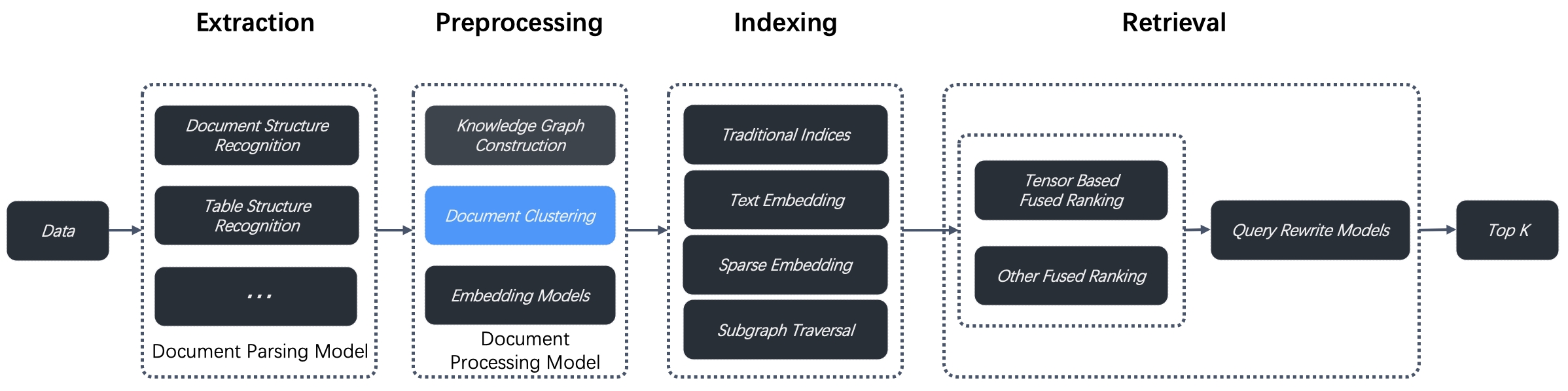
我们对这种新方法的测试表明,在需要复杂、多步推理的问答任务上,它达到了业界领先(SOTA)水平。通过将 RAPTOR 检索与我们内置的分块方法和/或其他检索增强生成(RAG)方法相结合,您可以进一步提高您的问答准确率。
启用 RAPTOR 需要大量的内存、计算资源和 token。
基本原理
在原始文档被分割成块之后,这些块会根据语义相似性进行聚类,而不是按照它们在文本中的原始顺序。然后,系统默认的聊天模型会将聚类后的块进行摘要,形成更高级别的块。这个过程是递归应用的,从下到上形成一个具有不同摘要级别的树状结构。如下图所示,初始的块构成了叶子节点(蓝色显示),并被递归地摘要成一个根节点(橙色显示)。
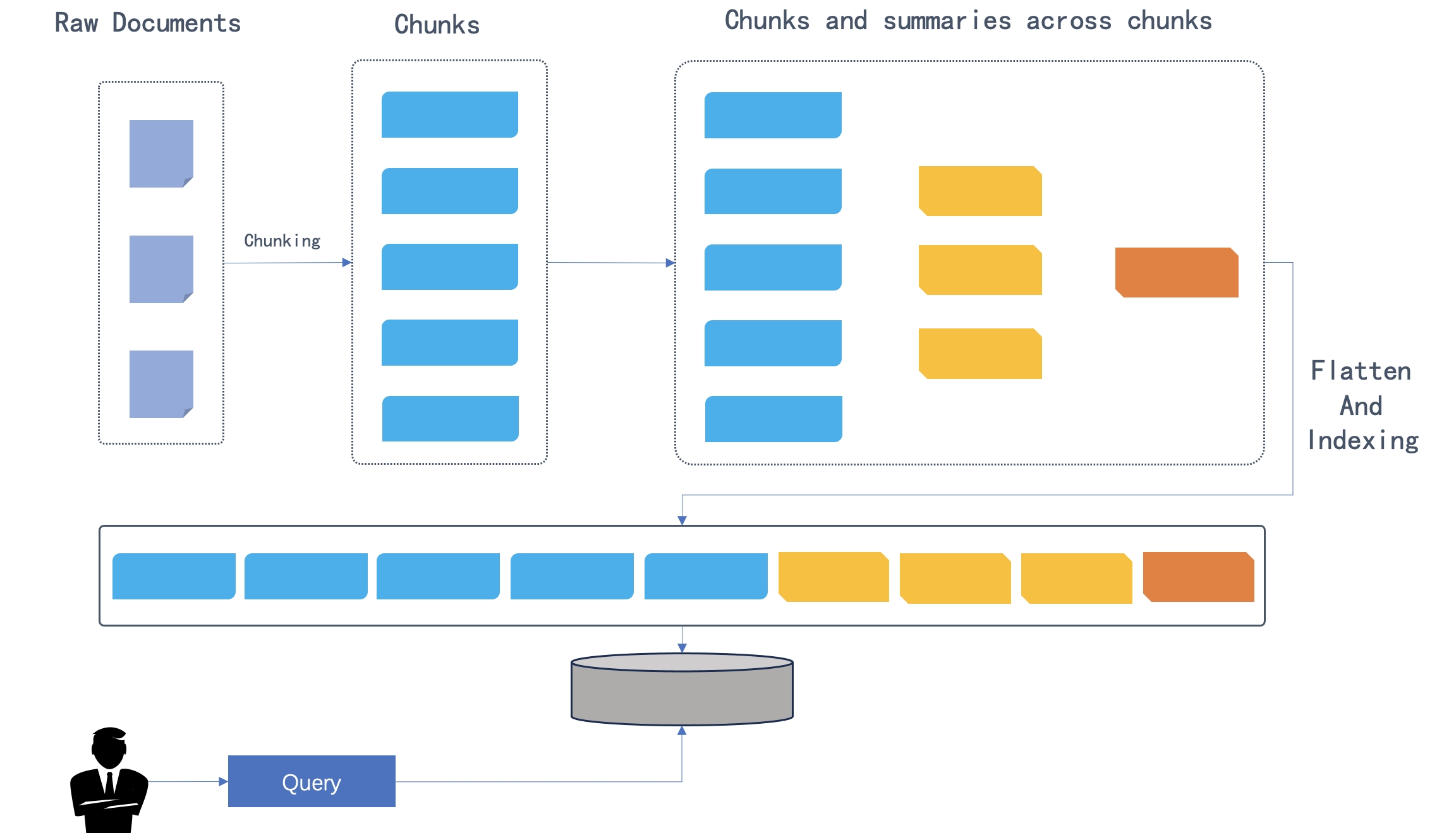
递归的聚类和摘要过程既能捕捉到广泛的理解(由根节点表示),又能保留多跳问答所需的精细细节(由叶子节点表示)。
使用场景
对于涉及复杂、多步推理的多跳问答任务,问题与其答案之间通常存在语义鸿沟。因此,直接用问题进行搜索往往无法检索到有助于得出正确答案的相关块。RAPTOR 通过为聊天模型提供更丰富、更具上下文感知和相关性的块来进行摘要,从而解决了这一挑战,实现了在不失精细细节的情况下进行整体理解。
知识图谱也可用于多跳问答任务。详情请参见构建知识图谱。您可以使用其中一种方法或两种都用,但请确保您了解所涉及的内存、计算和 token 成本。
前提条件
系统默认的聊天模型用于摘要聚类后的内容。在继续之前,请确保您已正确配置了聊天模型。
配置
RAPTOR 功能默认是禁用的。要启用它,请在知识库的**配置**页面上手动打开**使用 RAPTOR 增强检索**开关。
提示词
以下提示词将*递归地*应用于聚类摘要,其中 {cluster_content} 作为内部参数。我们建议您暂时保持原样。该设计将在适当的时候进行更新。
Please summarize the following paragraphs... Paragraphs as following:
{cluster_content}
The above is the content you need to summarize.
最大 Token 数
每个生成的摘要块的最大 Token 数。默认为 256,最大限制为 2048。
阈值
在 RAPTOR 中,块是按其语义相似性进行聚类的。**阈值**参数设置了块分组所需的最小相似度。
它默认为 0.1,最大限制为 1。较高的**阈值**意味着每个聚类中的块较少,而较低的阈值意味着块较多。
最大聚类数
要创建的最大聚类数。默认为 64,最大限制为 1024。
随机种子
一个随机种子。点击 **+** 来更改种子值。